
목록분류 전체보기 (408)
오답노트
 [Pandas] 데이터 프레임 병합, 붙이기
[Pandas] 데이터 프레임 병합, 붙이기
merge pd.merge(dataframe1,dataframe2,how,on,as_index) merge는 병합으로 SQL에서 join과 같다. key를 따로 지정하지 않으면 자동으로 지정한다. 인자로는 데이터프레임 2개를 받고 how 옵션은 merge할 방식을 left ,right, inner ,outer 으로 지정할 수 있다. 기본은 inner다. on 옵션은 병합의 기준이 될 행을 선택할 수 있다. 사용하지 않으면 자동으로 기준이 정해진다. left dataframe1을 기준으로 merge pd.merge(df1,df2,how="left") right dataframe2을 기준으로 merge pd.merge(df1,df2,how="right") inner dataframe1과 dataframe2에..
iterator 반복가능한 객체다 iter()를 통해 iterator를 만들 수 있다. it = iter([1,2,3]) type(it) # list_iterator next(it) # 1 next(it) # 2 next(it) # 3 next(it) # 에러발생 next 함수를 통해 itreator의 메모리 위치를 다음으로 바꿀 수 있다. it 에는 1,2,3이 있는데 next를 4번 호출하게 되면, it 밖에 메모리를 보게돼서 에러가 발생한다. class It: def __init__(self): self.prev = 0 self.curr = 1 def __iter__(self): return self def __next__(self): value = self.curr self.curr += self..
 [scrapy] XPath로 정적 페이지 웹 크롤링
[scrapy] XPath로 정적 페이지 웹 크롤링
scrapy 파이썬으로 웹페이지의 데이터를 수집하는 프레임워크이다. 정적페이지 웹 크롤링 우선 scrapy 프레임워크를 다운 받는다. !pip install scrapy 다운로드가 끝나면 scrapy 프로젝트를 생성한다. !scrapy startproject musinsa 프로젝트 생성에 성공하면 프로젝트 이름으로 폴더가 생성된다. 프로젝트 폴더 아래에 프로젝트 이름 폴더와 spider 폴더가 존재한다. - items.py : 수집할 데이터의 구조 정의 - middlewares.py : 데이터를 수집할 때 headers 정보와 같은 내용 설정 - pipelines.py : 데이터를 수집한 후에 코드 실행 정의 - settings.py : 크롤링에 대한 설정 :크롤링 시간 간격, robots.txt에 대한..
 [XPath] XPath
[XPath] XPath
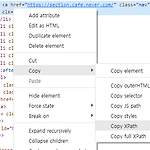
XPath XPath는 XML에서 사용하는 요소나 속성을 지정할 수 있다. scrapy에서는 XPath를 통해 Element를 지정할 수 있다. 문법 // : 최상위 Element = css selector : (.class p) *[@class = "class_sample"] : 속성값으로 Element 선택, @는 지정할 속성 " " 에는 속성에 대한 속성명이 입력된다. / : 한 단계 하위 Element = css selector : (.class > p) [n] : n 번째 Element 예시로 크롬 개발자 도구를 사용해 XPath를 가져오고 문법에 따른 관계를 살펴보자 Element에 우클릭 -> Copy -> Copy XPath 를 하면 클립보드에 XPath가 저장된다. //*[@id="NM_..
[selenium] selenium 간단 사용법 [selenium] selenium 간단 사용법 selenium selenium은 브라우저의 자동화 목적으로 만들어진 다양한 브러우저를 제어할 수 있도록 하는 라이브러리 selenium 사용준비 라이브러리 설치 !pip install selenium 파이썬에서 해당 소스를 실행시 dhjkl123.tistory.com selenium을 이용한 정적 페이지 웹 크롤링 무신사 상품 랭킹을 가져오는 실습을 통해 알아보자 from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get("https://www.musinsa.com..
 [selenium] selenium 간단 사용법
[selenium] selenium 간단 사용법
selenium selenium은 브라우저의 자동화 목적으로 만들어진 다양한 브러우저를 제어할 수 있도록 하는 라이브러리 selenium 사용준비 라이브러리 설치 !pip install selenium 파이썬에서 해당 소스를 실행시켜 selenium을 설치하자. webdriver 설치 https://chromedriver.chromium.org/downloads ChromeDriver - WebDriver for Chrome - Downloads Current Releases If you are using Chrome version 104, please download ChromeDriver 104.0.5112.79 If you are using Chrome version 103, please downl..
 [BeautifulSoup] 정적 페이지와 정적 페이지 웹 크롤링
[BeautifulSoup] 정적 페이지와 정적 페이지 웹 크롤링
정적 페이지 정적 페이지는 페이지에 변화가 있으면, URL에도 변화가 있는 페이지가 정적 페이지다. 정적 페이지 웹 크롤링 정적 페이지는 HTML에서 CSS Selector를 통해 웹 크롤링 할 수 있다. 무신사 상품 랭킹 목록을 크롤링 실습을 해보자. 1. bs 패키지를 먼저 설치한다. !pip install bs 2. https://www.musinsa.com/ranking/best?period=now&age=ALL 에 접속해서 개발자 도구(F12)를 열고, 최상위 Elements 탭을 연다. 3. Ctrl + Shift + C 또는 Elements 좌측에 마우스 커서 아이콘을 클릭하여 상품 이름을 클릭한다. 4. CSS Selector를 통해서 상품 브랜드, 상품명, 상품 가격에 대한 CSS Sel..
 [CSS] CSS Selector
[CSS] CSS Selector
CSS Selector HTML태그 3.텍스트 ~ 6.테이블관련 까지만 읽어도 해당 포스트를 이해하는데 문제는 없다. 시작 태그에는 id, class, attr가 존재하거나 태그명만 있는 경우가 있다. 위 4개 항목을 통해 Element를 선택할 수 있다. 기존 css에서 엘리먼트를 선택하는 방법은 아래와 같다. - tag이름 : span - id : #id - class : .class - attr : [value="val"] HTML로 살펴보자 span p_id p_class p_val style 태그 내부에 사용한 것이 CSS Selector 이다. n번째 선택 위 css selector 뒤에 :nth-child(n) 이 붙는다. n은 n번째를 의미한다. 주의해야할 점은 css selector로 선..
 [requests] 동적 페이지와 동적 페이지에 대한 웹 크롤링
[requests] 동적 페이지와 동적 페이지에 대한 웹 크롤링
동적 페이지 동적 페이지는 요즘 많이 쓰고있는 반응형 웹이 동적 페이지이다. 사용자가 버튼을 클릭하거나 상호작용, 이벤트가 발생해도 URL이 바뀌지 않고 바로 페이지 내에서 결과가 나타난다. 동적 페이지 웹 크롤링 웹 크롤링은 크게 동적 페이지에 대해서 또는 정적 페이지에 대해서 수행할 수 있다. 하지만 이 둘의 웹 크롤링 방법은 상당히 다르다. 동적페이지는 보통 json 형식으로 데이터를 크롤링할 수 있다. 리그 오브 레전드 전적 조회 사이트인 op.gg 에서 챔피언 목록을 웹 크롤링 실습을 통해 동적 페이지 웹 크롤링을 알아보자. 1. op.gg 챔피언 분석 탭 에 접속한다. 2. F12를 눌러 개발자 툴을 키고 가장 상위 탭 중에서 Network를 클릭한다. 그리고 바로 아래 탭에서 Fetch/XH..
requests 패키지 REST 방식을 사용할 수 있게 해주는 파이썬 패키지이다. 요약하면 URL로 정보를 요청해서 데이터를 받을 수 있다. get() HTTP 메소드 GET을 사용하는 함수다. GET의 특징은 URL에 파라미터가 들어간다는 점이다. URL로만으로 데이터를 가져오지 못하는 경우가 있는데, 이 때는 headers 속성에 referer 와 user-agent를 딕셔너리로 만들어 입력한다. import requests headers = { "referer": "https://www.op.gg/champions", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome..