
오답노트
[scrapy] XPath로 정적 페이지 웹 크롤링 본문
scrapy
파이썬으로 웹페이지의 데이터를 수집하는 프레임워크이다.
정적페이지 웹 크롤링
우선 scrapy 프레임워크를 다운 받는다.
!pip install scrapy
다운로드가 끝나면 scrapy 프로젝트를 생성한다.
!scrapy startproject musinsa
프로젝트 생성에 성공하면 프로젝트 이름으로 폴더가 생성된다.
프로젝트 폴더 아래에 프로젝트 이름 폴더와 spider 폴더가 존재한다.

- items.py : 수집할 데이터의 구조 정의
- middlewares.py : 데이터를 수집할 때 headers 정보와 같은 내용 설정
- pipelines.py : 데이터를 수집한 후에 코드 실행 정의
- settings.py : 크롤링에 대한 설정 :크롤링 시간 간격, robots.txt에 대한 규칙
- spiders : 디렉토리 : 크롤링 절차 정의
TextResponse 웹 크롤링
프로젝트를 만들었다면 TextResponse를 이용해서 크롤링해보자
url = "https://www.musinsa.com/ranking/best?period=now&age=ALL"
req = requests.get(url)
rsp = TextResponse(req.url,body =req.text,encoding = "utf-8")
links = rsp.xpath('//*[@id="goodsRankList"]/li/div[3]/div[2]/p[2]/a/@href').extract()
link = links[0]
headers = {
"referer" : 'https://www.musinsa.com/ranking/best?period=now&age=ALL',
"user-agent" : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
req = requests.get(link,headers = headers)
rsp = TextResponse(req.url,body=req.text,encoding="utf-8")
product_name = rsp.xpath('//*[@class = "product_title"]/em/text()')[0].extract()
product_price = rsp.xpath('//*[@id = "normal_price"]/text()')[0].extract()
print(product_name,product_price)여기서 힘들었던 점은 xpath로 상품 이름, 가격을 알아오는 것이였다.
분명 원본 페이지에서 Element를 확인해보면 xpath가 맞는데, 요청으로 받아온 결과에는 없는것..
그래서 크롬 개발자도구로 Network -> Response를 확인했더니 원본 페이지의 내용과 완전히 달랐다..
웹을 공부했더라면 금방 발견했을텐데..
Response의 내용을 토대로 xpath를 입력하니 원하는 값만 불러올 수 있었다.
또, headers 옵션은 귀찮더라도 꼭 추가하자.
spider 웹 크롤링
scrapy 프로젝트 폴더에 items.py를 다음과 같이 수정하자.
import scrapy
class MusinsaItem(scrapy.Item):
title = scrapy.Field()
price = scrapy.Field()
link = scrapy.Field()위에서 설명한 것과 같이 데이터의 구조를 나타낸다.
상품명, 가격, 상품 링크를 가져와서 csv로 만들것이다.
다음으로 setting.py 로 가서 아래 사진과 같이 수정한다.
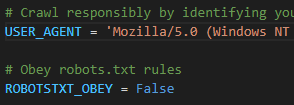
위와 같이 수정하는것은 필수는 아니지만, 크롤링하려는 사이트에 robots.txt 때문에 크롤링이 안되는 경우가 있다.
ROBOTSTXT_OBEY는 기본적으로 True다. 하지만 False로 바꾸면 크롤링하려는 사이트의 robots.txt를 무시하고 크롤링을 수행한다.
ROBOTSTXT_OBEY를 False로 바꾸고 잘 되면 좋지만, 아닐때도 있다..
어째서인지 모르겠지만 코드에서 headrs옵션에 headrs를 줬는데도 제대로 크롤링하지 않는다.. (setting.py 가 더 상위라서..?) 하지만 USER_AGENT 옵션에 직접 입력하면 코드와 상관없이 제대로 응답 받을 수 있다.
다음은 spider 폴더 내에 spider.py 를 아래와 같이 수정한다.
import scrapy
from musinsa.items import MusinsaItem
class MSSSpider(scrapy.Spider):
name = "musinsa"
allow_domain = ["musinsa.com"]
start_urls = ["https://www.musinsa.com/ranking/best?period=now&age=ALL"]
def parse(self,response):
links = response.xpath('//*[@id="goodsRankList"]/li/div[3]/div[2]/p[2]/a/@href').extract()
headers = {
"Referer" : 'https://www.musinsa.com/ranking/best?period=now&age=ALL',
"User-Agent" : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
for link in links[:20]:
yield scrapy.Request(link,callback=self.parse_content,headers=headers)
def parse_content(self, response):
item = MusinsaItem()
item["title"] = response.xpath('//*[@class = "product_title"]/em/text()')[0].extract()
item["price"] = response.xpath('//*[@id = "normal_price"]/text()')[0].extract()
item["link"] = response.url
yield item- name : 터미널로 scrapy spider를 실행시킬 때 사용하는 이름이다.
- start_urls : 상품의 링크를 얻기위해 필요한 url이다.
- parse : start_urls로 받아온 상품의 링크에 요청을 보내 응답을 받는다.
- scrapy.Request : 상품의 링크에 요청을 보내 응답을 받으면 parse_content 함수를 실행시킨다.
- parse_content : items.py에 정의한 데이터 형식으로 만드는 함수다.
이제 터미널을 열고 cd 명령어를 통해 scrapy 프로젝트 파일로 이동한다.
그리고 scrapy crawl musinsa -o items.csv 입력한다.


scrapy 프로젝트에 items.csv가 생성된걸 확인할 수 있다.
pandas 데이터프레임으로 확인하면 아래 사진과 같다.

'Python > Web Crawling' 카테고리의 다른 글
| 네이버 카페 크롤링 (0) | 2022.12.05 |
|---|---|
| [XPath] XPath (0) | 2022.08.06 |
| [selenium] 정적 페이지와 정적 페이지 웹 크롤링 (0) | 2022.08.05 |
| [selenium] selenium 간단 사용법 (0) | 2022.08.05 |
| [BeautifulSoup] 정적 페이지와 정적 페이지 웹 크롤링 (0) | 2022.08.05 |


