
목록분류 전체보기 (413)
오답노트
 [seaborn] 복합 차트
[seaborn] 복합 차트
[seaborn] seaborn 과 차트들 [seaborn] seaborn 과 차트들 seaborn Matplotlib을 기반의 시각화 패키지이다. 차트 histplot sns.histplot(data = titanic, x='Age', bins = 16) plt.show() data 옵션에는 데이터프레임 x 옵션에는 데이터프레임에서 히스토그램으로 나타내.. dhjkl123.tistory.com distplot sns.hist 함수와 sns.kdeplot 이 합쳐서 나오는 결과다. sns.distplot(titanic['Age'], bins = 16, hist_kws = dict(edgecolor='grey')) plt.show() 인자로 시리즈를 받는다. bis 옵션으로 hist의 분해능을 설정 가능하..
 [seaborn] seaborn 과 차트들
[seaborn] seaborn 과 차트들
seaborn Matplotlib을 기반의 시각화 패키지이다. 차트 histplot sns.histplot(data = titanic, x='Age', bins = 16) plt.show() data 옵션에는 데이터프레임 x 옵션에는 데이터프레임에서 히스토그램으로 나타내고 싶은 시리즈 명을 입력 bins는 분해능 sns.histplot(data = titanic, x='Age', bins = 16, hue = 'Survived') plt.show() hue 옵션을 통해서 두 개의 데이터를 같이 표현할 수 있다. 범주형 데이터일수록 더 깔끔한 결과가 나온다. kdeplot sns.kdeplot(data = titanic, x = 'Age', hue = 'Survived') plt.show() data 옵션..
 [matplotlib] 범주형 데이터 시각화
[matplotlib] 범주형 데이터 시각화
[데이터 분석] 범주형 데이터 분석 [데이터 분석] 범주형 데이터 분석 범주형 데이터 수치형 데이터와 반대로 수학적 계산이 되지 않는 데이터들을 의미한다. 계절이나 등급, 월 같은 경우가 범주형 데이터에 해당한다. 범주형 데이터 기초통계량 pandas 함수로 쉽게 dhjkl123.tistory.com bar plt.bar(Serise.value_counts().index,Serise.value_counts().values) plt.barh(Serise.value_counts().index,Serise.value_counts().values) pandas 의 value_counts()를 통해 범주형 데이터의 집계 작업 후, index와 values를 차례대로 bar함수에 인자로 넣으면 표가 나타난다. ba..
범주형 데이터 수치형 데이터와 반대로 수학적 계산이 되지 않는 데이터들을 의미한다. 계절이나 등급, 월 같은 경우가 범주형 데이터에 해당한다. 범주형 데이터 기초통계량 pandas 함수로 쉽게 기초 통계량을 알 수 있다. 범주형데이터시리즈.value_counts()/데이터프레임.shape[0] 범주형 데이터/데이터프레임 행의 수 위와 같은 방법으로 기초통계량을 구할 수 있다. 범주형 데이터의 기초통계량은 퍼센트로 나타내진다. 주의할 점으로 범주형 데이터에 NaN이 있으면 계산이 제대로 되지 않는다. 꼭 결측치를 처리하고 기초통계량을 구하도록 하자. print(titanic['Survived'].value_counts()/titanic.shape[0]) ''' 0 0.616162 1 0.383838 '''
 [matplotlib] 수치형 데이터 시각화
[matplotlib] 수치형 데이터 시각화
[데이터 분석] 수치형 데이터 분석 [데이터 분석] 수치형 데이터 분석 수치형 데이터 숫자로써 의미를 가지는 데이터를 수치형 데이터라고 한다. 예를 들어 가격 데이터가 있다. 수치형 데이터인지 모호할 때는 사칙연산을 해보면 알수있다. 1000원 과 2000원을 비교 dhjkl123.tistory.com 히스토그램(hist) plt.hist(시리즈,bins,edgecolor) hist 함수는 데이터에 대한 빈도수를 바 그래프 형태로 나타낸다. 시리즈를 인자로 받아 해당 시리즈의 빈도수를 바 그래프 형태로 볼 수 있다. bins는 분해능을 결정할 수 있다. 입력한 숫자가 높을 수록 높은 분해능을 보인다. edgecolor는 바의 테두리 색을 결정할 수 있다. plt.hist(df['Fare'],bins=32..
 [데이터 분석] 수치형 데이터 분석
[데이터 분석] 수치형 데이터 분석
수치형 데이터 숫자로써 의미를 가지는 데이터를 수치형 데이터라고 한다. 예를 들어 가격 데이터가 있다. 수치형 데이터인지 모호할 때는 사칙연산을 해보면 알수있다. 1000원 과 2000원을 비교했을때 1000원 의 2배는 2000원이다. 반대로 범주형 데이터는 사칙연산을 하면 그 의미가 맞지 않는다. 예를 들어 월 데이터가 있으면, 1월의 2배가 2월이 되지 않는다. 수치화 대표값 평균 산술평균 : (a1 + a2 + a3 + ... + an) /n 조화평균 : 2*a*b / (a+b) 중앙값 : 자료의 순서상 가운데 위치하는 값 자료의 개수가 짝수일 경우 두 중간값의 중간이 중간값이 된다. 최빈값 : 자료에서 나타나는 빈도수 4분위수 : 데이터에서 최소값, 1/4, 2/4, 3/4, 최대값에 있는 값을..
 [matplotlib] 여러 그래프 나누어 그리기
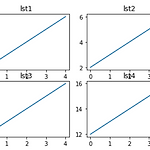
[matplotlib] 여러 그래프 나누어 그리기
sublpot plt.subplot(row, col, index) row : 세로로 생성할 차트 개수 col : 가로로 생성할 차트 개수 index : 차트의 위치 (1부터 시작) subplot은 여러 차트를 한번에 출력할 수 있다. plot 함수를 사용하기 전에 먼저 호출하여 사용해야한다. 다음 subplot을 만나기전까지 plot에 plt 함수가 적용된다. lst1 = list(range(1,6)) lst2 = list(range(2,7)) lst3 = list(range(11,16)) lst4 = list(range(12,17)) plt.subplot(2,2,1) plt.plot(lst1) plt.title("lst1") plt.subplot(2,2,2) plt.plot(lst2) plt.title..
 [matplotlib] 차트 조정과 그리기
[matplotlib] 차트 조정과 그리기
조정 xlim, ylim xlim, ylim 함수는 각각 x축, y축 최대 최소값을 지정할 수 있다. 들어간 데이터가 범위와 상관없이 위 함수로 정해진 범위만 나타낸다. plt.plot('lst2','lst1',data=dict1) plt.xlim(0,10) plt.ylim(0,10) plt.show() figure 함수는 차트의 실제 크기를 조절할 수 있다. figsize 에 옵션으로 (x, y) 형태에 튜플을 입력하면 가로가 x 세로가 y인 크기의 차트로 바꾼다 주의할 점은 plot 함수가 호출되기 전에 호출해야한다. 그렇지 않으면 변경되지 않는다. plt.figure(figsize=(3,3)) plt.plot('lst2','lst1',data=dict1) plt.show() 그리기 axhilne, ..
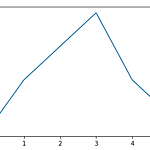 [matplotlib] matplotlib와 차트 그리기
[matplotlib] matplotlib와 차트 그리기
matplotlib 데이터의 시각화를 위해서 파이썬에서 사용가능한 라이브러리 차트 그리기 list 데이터 그리기 import matplotlib.pyplot as plt lst = [1,4,6,8,4,2] plt.plot(lst) plt.show() plot 함수에 리스트를 입력후 show 함수를 호출 하면 아래와 같은 결과가 출력 된다. lst1 = [1,4,6,8,4,2] lst2 = list(range(1,7)) plt.plot(lst2,lst1) plt.show() 위 코드는 x축 데이터를 위한 리스트를 먼저 만들고 x축을 지정하였다. 사진 2.1.1 과 비교해보자 dict 데이터 그리기 dict1 = { "lst1" : lst1, "lst2" : lst2, 'lst3' : [8,4,5,1,2,5..
 [sklearn] MinMaxScaler
[sklearn] MinMaxScaler
MinMaxScaler MinMaxScaler는 열에서 최소값을 0, 최대값을 1로 봤을 때, 그 비율로 Scale을 조정할 수 있도록 하는 객체다. from sklearn.preprocessing import MinMaxScaler col = list(df.iloc[:,-2:]) scale = MinMaxScaler() df_scale = scale.fit_transform(df.iloc[:,-2:]) df_scale = pd.DataFrame(df_scale,columns=col) result = pd.concat([df.iloc[:,:1],df_scale],axis=1) 그림 1.1 에서 Serise1을 보면 3번 인덱스의 값이 가장 크고, 0번 인덱스 값이 가장 작다. 그림 2.2 에서 Seris..