
오답노트
[NLP] 워드 임베딩 (Word Embedding)과 Word2Vec 본문
09. 단어의 표현 방법
이번 챕터에서는 자연어 처리에서 필수적으로 사용되는 단어의 표현 방법인 원-핫 인코딩(One-hot encoding)과 워드 임베딩(Word Embedding)에 대해서 학 ...
wikidocs.net
희소 표현 (Sparse Representation)
어떤 단어를 표현할 때, One-Hot Vector 형식으로 표현한 것을 희소 표현이라고 한다.
One-Hot Vector는 단어가 100개가 있을 때, 99개의 0과 1개의 1로 표현하는 방법이다.
단점으로는 단어가 많아지면 차원이 많아져 공간 낭비가 있다.
밀집 표현 (Dense Representation)
희소표현은 단어의 개수만큼 차원이 많아졌지만, 밀집 표현은 사용자가 직접 차원을 정의할 수 있고, 정의된 차원에 따라 실수 값으로 이루어진 벡터로 단어를 표현할 수 있다.
이를 dense vector라고 한다.
분산 표현 (Distributed Representation)
분산 표현은 비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다는 분포 가설에서 만들어진 표현 방법이다.
분산 표현을 이용하여 단어의 유사도를 벡터화하는 작업은 워드 임베딩 작업에 속하기 때문에 이렇게 표현된 벡터 또한 임베딩 벡터라고 하며, 저차원을 가지므로 밀집 벡터에도 속한다.
워드 임베딩
워드 임베딩은 단어를 벡터로 표현하는 것이다.
위에서 설명한 밀집 벡터를 사용하므로 중요한 정보만 남기고 적은 차원에서 단어를 표현하고 기계학습에서 자질로 사용할 때 처리하기 쉽다는 장점이 있다.
Word2Vec
단어간 유사도를 반영할 수 있도록 단어의 의미를 벡터화하는 방법이다.
Word2Vec을 수행하는 알고리즘은 CBOW(Continuous Bag of Words)와 Skip-gram이 있다.
CBOW(Continuous Bag of Words)
CBOW는 주변에 있는 단어들로 중간에 있는 단어들을 예측하는 방법이다.
이 때, 예측하는 단어를 중심 단어(Center Word), 예측에 사용되는 단어를 주변 단어(Context Word)라고 한다.
중심 단어부터 앞,뒤로 몇개의 단어를 주변 단어로 선택할지 정하는 단위를 윈도우라고한다.
"The fat cat sat on the mat"
위의 문장을 예로 들었을 때, 중심단어는 'sat'이고 윈도우를 2로 정했다면, 'fat' 'cat' 그리고 'on' 'the' 가 주변 단어가 된다.
위 과정을 중심단어가 'The'부터 'mat'이 될 때까지 진행한다. 이 방법을 슬라이딩 윈도우라고 한다.

우선 Word2Vec을 진행하려면 단어들을 One-Hot Vector로 변환해야한다.
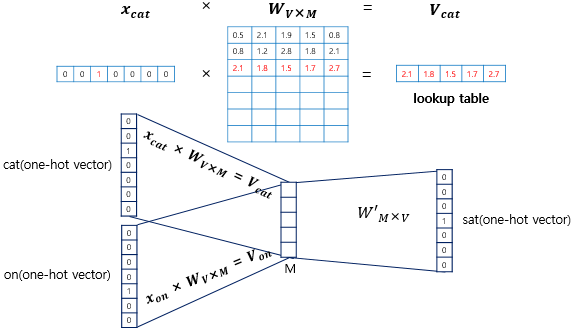
중간에 은닉층과는 다른 투사층이라는 활성화 함수가 존재하지 않고 look up table이라는 연산을 담당하는 layer가 존재한다.
M은 투사층의 크기로 위 사진에서 각 단어의 임베딩 벡터의 차원은 5가 된다.
입력층과 투사층의 가중치 W는 V * M 행렬로 V는 단어의 개수(또는 차원)이다. 이 가중치 행렬에 One-Hot Vector 곱하면 해당 벡터의 가중치가 출력되기 때문에 look up table이라고 한다.
이 투사층을 통해 주변단어와 가중치가 곱한 값의 평균으로 중심단어를 예측한다. 이때 중심단어는 softmax로 벡터 내부의 각 자리의 확률로 예측된다. 확률이 제일 높은 원소 자리와 실제 벡터의 자리와 일치 할 때까지 계속 학습을 하게 되는 원리이다.
Skip-gram
CBOW와 차이점은 input이 주변단어가 아닌 중심단어인 것 그리고 output이 중심단어가 아닌 주변단어인 것이다.
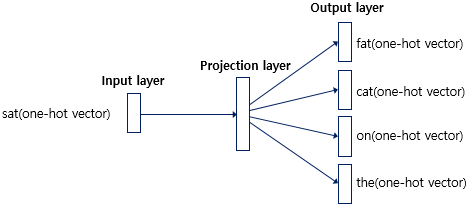
그리고 성능적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져있다.
'Python > DL' 카테고리의 다른 글
| [NLP] RNN (Recurrent Neural Network) (0) | 2022.10.06 |
|---|---|
| [NLP] CNN 기반 텍스트 분류 (0) | 2022.10.06 |
| [NLP] 문서 클러스터링 (0) | 2022.10.04 |
| [NLP] 문서 분류 (KNN, 나이브 베이즈) (0) | 2022.10.04 |
| [NLP] 문서 벡터화 & 문서 유사성 (0) | 2022.10.04 |

