
오답노트
[NLP] CNN 기반 텍스트 분류 본문
https://dhjkl123.tistory.com/270?category=966550
[DL] CNN (Convolutional Neural Network)
이미지 컴퓨터에서 표현하는 이미지는 픽셀 단위의 숫자로 되어 있다. 색이 없는 흑백은 1채널 색이 있는 RGB는 3채널로 이루어져 있다. CNN CNN 은 요약해서 말하자면 n*n 필터를 거쳐서 feature map을
dhjkl123.tistory.com
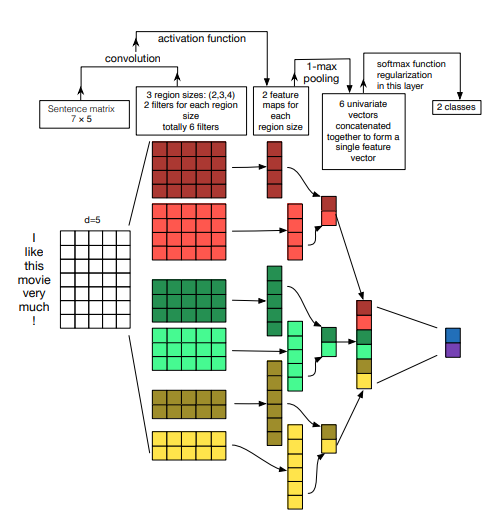
CNN 기반 텍스트 분류
CNN은 문장의 위치 정보를 보존하면서 각 문장 성분의 등장 정보를 학습에 반영하는 구조이다.
- 워드 임베딩으로 단어를 벡터로 만든다.
- 벡터의 차원 * 같이 볼 단어의 개수 만큼의 커널로 합성곱을 계산한다.
- 2번에서 만들어진 값에 max pooling으로 최대값을 추출한다.
- 2~3과정을 거친 다른 합성곱 결과들을 합친다. (concatenate)
- fully connected에서 softmax를 통해 분류한다.
PyTorch 실습
# torchtext.legacy를 사용할 수 있는 torchtext 버전 설치
!pip install -U torchtext==0.10.0
#colab 을 이용한 실행시
from google.colab import drive
drive.mount('/content/gdrive')
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torchtext.legacy import data
import torchtext.datasets as datasets
class CNN_Text(nn.Module):
def __init__(self,embed_num,class_num):
super(CNN_Text, self).__init__() # nn.Module의 변수 상속
# V: 사전의 크기
# D: embed_dim
# C: 분류하고자 하는 클래스의 개수
# Co : 각 커널(필터)의 갯수
V = embed_num
D = 100
C = class_num
Co = 100
Ks = [3,4,5]
self.embed = nn.Embedding(V,D)
self.convs1 = nn.ModuleList([nn.Conv2d(1,Co,(K,100)) for K in Ks])
self.dropout = nn.Dropout(0.2)
self.fc1 = nn.Linear(len(Ks)*Co,C)
def forward(self, x):
x = self.embed(x)
x = x.unsqueeze(1)
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs1]
x = [F.max_pool1d(i,i.size(2)).squeeze(2) for i in x]
x = torch.cat(x,1)
x = self.dropout(x)
logit = self.fc1(x)
return logit
class mydataset(data.Dataset):
@staticmethod
def sort_key(ex):
return len(ex.text)
def __init__(self, text_field, label_field, path=None, examples=None, **kwargs):
fields = [('text', text_field),('label',label_field)]
if examples is None:
path = self.dirname if path is None else path
examples = []
for i,line in enumerate(open(path,'r',encoding='utf-8')):
if i==0:
continue
line = line.strip().split('\t')
txt = line[1].split(' ')
examples += [data.Example.fromlist([txt,line[2]],fields)]
super(mydataset, self).__init__(examples,fields,**kwargs)
text_field = data.Field(batch_first = True,fix_length=20) # 전처리 관련 field 객체 생성 / fix_length : 하나의 문장 내 max 토큰 수
label_field = data.Field(sequential=False,batch_first = True, unk_token = None) # 전처리 관련 field 객체 생성 / sequential : 시퀸스데이터 여부
train_data = mydataset(text_field,label_field,path='/content/gdrive/My Drive/Colab Notebooks/train_tok.txt')
test_data = mydataset(text_field,label_field,path='/content/gdrive/My Drive/Colab Notebooks/test_tok.txt')
text_field.build_vocab(train_data)
label_field.build_vocab(train_data)
train_iter, test_iter = data.Iterator.splits(
(train_data,test_data),batch_sizes=(100,1)
)
print(len(text_field.vocab))
cnn = CNN_Text(len(text_field.vocab),2)
optimizer = torch.optim.Adam(cnn.parameters())
cnn.train() #학습 모드
for epoch in range(20):
totalloss = 0
for batch in train_iter:
optimizer.zero_grad() # 그래디언트 초기화
txt = batch.text
label = batch.label
pred = cnn(txt)
loss = F.cross_entropy(pred,label)
totalloss += loss.data
loss.backward()
optimizer.step()
print(epoch,'eopch')
print('loss : {:.3f}'.format(totalloss.numpy()))
from sklearn.metrics import classification_report
cnn.eval() # 검증 모드
correct = 0
incorrect = 0
y_test = []
prediction = []
for batch in test_iter:
txt = batch.text
label = batch.label
y_test.append(label.data[0])
pred = cnn(txt)
_,ans = torch.max(pred,dim=1)
prediction.append(ans.data[0])
if ans.data[0] == label.data[0]:
correct += 1
else :
incorrect += 1
print('correct : ',correct)
print('incorrect : ',incorrect)
print(classification_report(torch.tensor(y_test),
torch.tensor(prediction),
digits=4,
target_names=['negative','positive']))
'Python > DL' 카테고리의 다른 글
| [NLP] Long Short-Term Memory (LSTM) (1) | 2022.10.06 |
|---|---|
| [NLP] RNN (Recurrent Neural Network) (0) | 2022.10.06 |
| [NLP] 워드 임베딩 (Word Embedding)과 Word2Vec (1) | 2022.10.05 |
| [NLP] 문서 클러스터링 (0) | 2022.10.04 |
| [NLP] 문서 분류 (KNN, 나이브 베이즈) (0) | 2022.10.04 |
'Python/DL' Related Articles
more


