
오답노트
[NLP] 문서 벡터화 & 문서 유사성 본문
문서의 표현
Bag of Words
문서를 단어의 집합으로 간주한다. 문서에 나타나는 각 단어는 feature로 간주되고 단어의 출현 빈도에 따른 가중치를 얻는다.
Feature Selection
Feature Selection은 학습 문서에 출현한 용어(term)의 부분 집합을 선택하는 것이다.
사전의 크기를 줄여서 학습에 더 효율적인 분류기를 만들고 Noise feature를 제거하여 분류의 정확도를 높인다.
Term Extraction
Term Extraction은 문서를 Term 단위로 분해하거나, 문서에서 Term을 추출하는 것이다.
추출 단위는 어절(띄어쓰기 단위), 형태소(형태소 분석) 등이 있다.
어떠한 Document가 있으면 Term Extraction을 통해 추출 단위에 따른 Term을 추출하고 Term Ordering을 통해 Term을 정렬한다.
Term Ordering이 완료된 Term들을 Term Vocabulary이라고 한다. 이 Term Vocabulary를 통해 Term ID를 생성한다.
Term ID는 Term Vocabulary의 순서 대로 숫자를 매기는 것이다.
Stop Word List
너무 자주 출현하기 때문에 문서를 변별하는 Feature로서 쓸모 없는 단어를 제외하는 리스트다.
대부분의 문장에 자주 등장하는 고빈도의 단어들이 List로 만들어진다.
하지만 해당 분야와 의미상 관련된 용어는 포함시켜야 한다.
Document Weighting
가중치 벡터로 문서를 표현한다.
Weighting 기법에는 TF 또는 TF * IDF 기법이 존재한다.
Term Frequency (TF)
각 Document에서 Term이 등장하는 빈도를 TF (Term Frequency) 라고 한다.
Inverse Document Frequency (IDF)
우선 Document Frequency 는 Term이 전체 Document에서 나오는 빈도이다.
Inverse Document Frequency는 Document Frequency의 역수이다.
TF-IDF 값
TF와 IDF를 결합하여 각 용어의 가중치를 계산하는 방법이다.
문서 D에서 나타난 용어 t에 부여되는 가중치를
TF-IDF(t,D) = TF * IDF 로 표현할 수 있다.
적은 수의 문서에서 용어 t가 많이 나타날 때 가장 높은 값을 가진다.

문서 유사성
Document를 Term Space의 Vector로 가정하고 Document Vector간 유사도를 계산하여 유사성을 비교한다.
문서 유사성 계산은 Cosine Similarity를 이용한다.
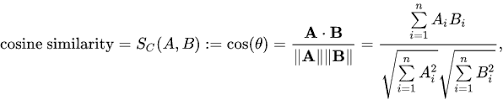
'Python > DL' 카테고리의 다른 글
| [NLP] 문서 클러스터링 (0) | 2022.10.04 |
|---|---|
| [NLP] 문서 분류 (KNN, 나이브 베이즈) (0) | 2022.10.04 |
| [NLP] 규칙/패턴 기반 자연어 처리 (0) | 2022.10.04 |
| [MeCab] 형태소 분석 (0) | 2022.10.03 |
| [NLP] 형태소 분석과 품사 태깅 (1) | 2022.10.03 |