
오답노트
[RS] 추천시스템 평가지표 - 순위 지표 본문
순위 지표
순위 지표는 추천 시스템이 제공하는 추천 결과의 순서와 실제 사용자의 선호도 순서 간의 유사성을 측정하는 지표다.
순위 지표는 일반적으로 정확도 지표와는 달리, 추천 결과가 아이템 리스트의 어떤 위치에 있는지에 초점을 둔다. 이러한 이유로, 순위 지표는 추천 시스템의 실제 사용 상황을 잘 반영한다.
MAP (평균 정밀도, Mean Average Precision)
MAP는 Precision@k의 평균 값이다. 여기서 k는 추천 리스트에서 고려하는 상위 k개의 아이템이다. MAP는 추천 시스템이 추천한 아이템 중 실제로 관심 있는 아이템이 있는 비율에 초점을 둔다.
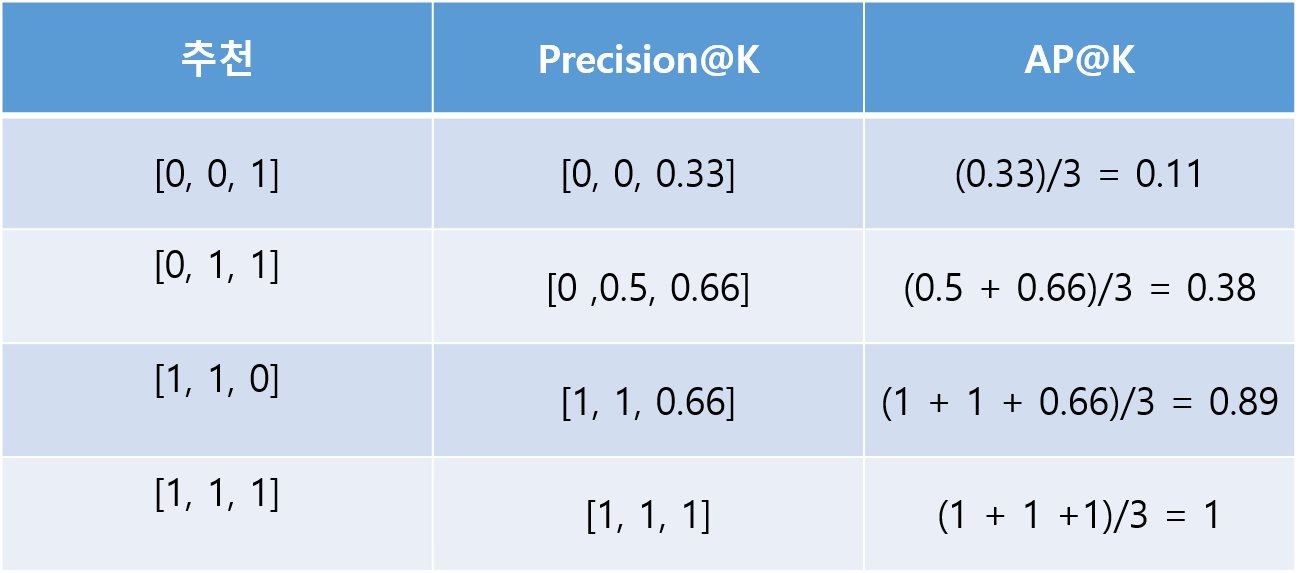
위 그림에서 추천은 각 인덱스는 사용자에 추천할 아이템이고 0은 모델이 추천하지 않는 것, 1은 모델이 추천했음을 의미한다. 첫번째 경우를 보면 실제로 사용자는 0, 1, 2순으로 아이템을 선호한다. 하지만 그중에 0번 1번은 예측하지 못했고 2번만 예측한 상황이다. 이때 Precision@k를 살펴보자. 0번 아이템 같은 경우 1개 중에 1개도 맞추지 못했으므로 0이다. 1번 같은 경우도 0번과 마찬가지로 2개 중에 1개도 맞추지 못했으므로 0이다. 마지막 2번 아이템은 3개중에 1개를 맞췄기 때문에 0.33의 정밀도를 갖는다.
그 다음을 보면 0번은 1개중 0개를 맞춰서 0, 1번은 2개중 1개를 맞춰서 0.5, 2번은 3개중 2개를 맞춰서 0.66..
이런 방법으로 얻은 Precision@k를 평균을 내면 AP@k를 얻을 수 있다.
이렇게 한명의 사용자로 부터 AP@k를 구할 수 있는데 여러 명의 사용자의 AP@k의 평균이 MAP이다.
MAP는 추천 시스템의 성능을 종합적으로 평가할 수 있는 지표다. Precision@k가 상위 k개의 추천 아이템 중 실제 관심 있는 아이템이 얼마나 있는지를 나타내기 때문에, MAP는 추천 시스템이 얼마나 관련성 높은 아이템을 추천하는지를 평가할 수 있다.
하지만 MAP는 모든 사용자의 Average Precision@k의 평균 값이기 때문에, 각각의 사용자의 특성에 따라 MAP가 차이가 있을 수 있습니다. 따라서, 사용자 그룹 별로 MAP를 계산하여 평가하는 것이 더 정확한 평가 방법일 수 있다.
NDCG (Normalized Discounted Cumulative Gain)
NDCG는 검색 알고리즘에서 성과를 측정하는 평가 함수인데, 추천 시스템에서는 추천된 아이템 리스트에서 실제로 사용자가 관심 있는 아이템이 얼마나 높은 위치에 있는지를 고려한다.
NDCG를 이해하기 위해서는 Cumulative Gain과 Discounted Cumulative Gain을 이해할 필요가 있다.
CG (Cumulative Gain)
CG는 Relevance의 합이다. Relevance란 사용자가 특정 아이템과 임의의 기준으로 얼마나 관련 있는지를 나타내는 값이다.
예를 들어 5개의 아이템이 사용자와의 관계를 나타내면 [3,2,0,0,1] 이라고 하자 그렇다면 CG의 값은 다음과 같다.

CG는 단순히 임의의 기준으로 사용자와 아이템의 관련도를 나타내는 값이므로 순서와는 아무런 관련이 없다.
DCG (Discounted Cumulative Gain)
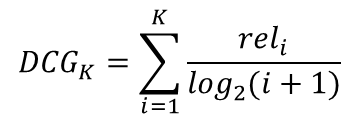
DCG는 CG에 순서에 따른 할인 개념을 도입한 것이다. 여기서 할인이란 아이템의 순서가 뒤에 있을 수록 분모가 커져 전체 DCG에 영향을 적제 주도록 하는 것이다. 하지만 사용자 별로 추천 아이템의 수가 다른 경우 정확한 성능 평가가 어렵다는 한계가 존재한다.
NDCG (Normalized Discounted Cumulative Gain)
DCG의 한계를 보완하기 위해 DCG에 정규화를 적용한 것이 NDCG이다. NDCG의 정규화를 위해 DCG에 IDCG를 나누는 것을 확인할 수 있다.
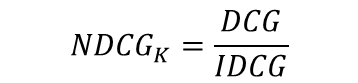
IDCG는 최선의 추천을 받았을 때 DCG값이다.
NDCG는 보통 0에서 1 사이의 값을 가지며, 높을수록 추천 시스템의 성능이 좋다고 평가된다. NDCG는 추천 시스템에서 개인화된 평가를 고려할 수 있기 때문에, 일반적으로 사용자 경험을 반영하는 평가 지표로 자주 사용한다.
Hit Rate
Hit rate는 다음과 같은 방식으로 산출한다.

학습전 사용자가 선호하는 아이템 중 1개를 임의로 골라 제거한 후 학습을 진행한다.
그 후 사용자의 선호하는 아이템을 예측했을 때, 위에서 제거한 아이템을 예측했다면 Hit로 본다.
위 과정을 모든 사용자들에게 진행했을 때, 모든 사용자 중에 hit된 사용자의 비율이 Hit Rate다.
'Python > ML' 카테고리의 다른 글
| [RS] 추천시스템 평가지표 - 정확도 지표 (0) | 2023.03.04 |
|---|---|
| [RS] 협업 필터링 (Collaborative Filtering) (0) | 2023.03.03 |
| [RS] 컨텐트 기반 필터링 (Content-based Filtering) (0) | 2023.03.02 |
| [ML] Boosting - CatBoost 실습 (2) | 2022.09.11 |
| [ML] Boosting - CatBoost 이론 (0) | 2022.09.09 |


