
오답노트
[ML] Boosting - CatBoost 이론 본문
CatBoost
CatBoost 알고리즘은 분류 모델을 만들 때 유용한 최근 알고리즘이다. 기존 Boosting 알고리즘의 문제점을 극복하는 알고리즘이다.
기존 Boosting의 한계
Prediction Shift
train data에서의 조건부 확률과 test data에서 조건부 확률간 차이가 있다.
Target Leakage
target을 예측하기 위해 모델링을 할 떄, train data의 target이 모델에 영향을 준다. 하지만 실제 예측을 할 때는 target이 없는 모순이 존재하게 된다.
기존 Boosting 극복
Ordered Target Statistics 과 Ordered Boosting으로 위 한계를 극복하려고 한다.
두 개념은 학습에 사용될 객체들을 시계열 데이터가 아니더라도 가상의 시간 개념을 도입하여 random permutation 한 것을 전제로 한다.
Ordered Target Statistics
Oredered TS(Target Statistics) 는 Target Leakage를 극복하기 위해 도입된 개념이다.
Greedy Target Statistics without Smoothing
우선 Greedy Target Statistics without smoothing을 먼저 알아야 한다. 범주형 변수를 가변수화 하지 않고, 범주가 가지는 y의 평균으로 볌주형 변수를 수치형 변수로 바꾸는 방법이다.
하지만 범주형 변수 중 극단적인 경우 (단 한번만 존재하는 경우 등)가 존재할 때, 수치형 변수로 바꿀 때 이상치로 변환되는 경우가 있다.
Greedy Target Statistics with Smoothing
그래서 Smooting을 통해서 이상치를 보정한다. 하지만 극단적인 경우에서 target에 의존하기 때문에, 상수 p로 변수가 결정되는 경우가 발생한다.
Ordered Target Statistics 공식
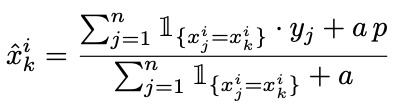
- a : 파라미터
- p : 이전 target 중 target이 1인 경우
- 분자 : 이전의 자기 자신이 등장한 수
- 분모 : 이전의 자기 자신이 등장했을 때, target이 1인 수
기존에 자기 자신의 target 값을 사용하여 TS하는 것이 아닌, 이전의 target 값으로 TS하기 때문에 Target Leakage를 방지할 수 있다.
Ordered Boosting
Ordered Boosting은 Prediction Shift를 극복하기 위해서 도입된 개념이다.
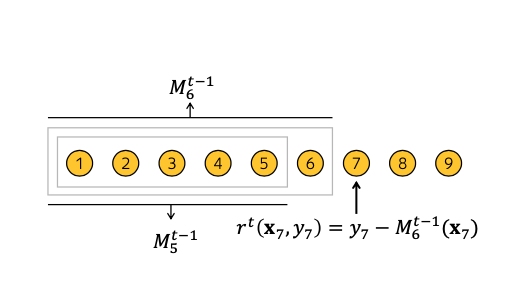
객체들을 통해 모델을 만들고 모델을 만들 때 사용되지 않은 한 개의 객체로 예측한 값과 객체의 실제 값의 차, 즉 잔차를 구한다.
이 때 모델은 실제 값의 영향을 받지 않게 된다.
Oblivious Tree
기본적인 트리 방식은 Asymmetric Tree 방식이다.
하지만 Ordered Boosting에서 사용되는 모델은 Oblivious Tree이다. Oblivious Tree는 트리를 분할할 때, 동일한 분할 기준이 전체 트리 레벨에 적용된다. 이는 균형잡힌 트리를 만들며, Overfitting을 방지할 수 있다.
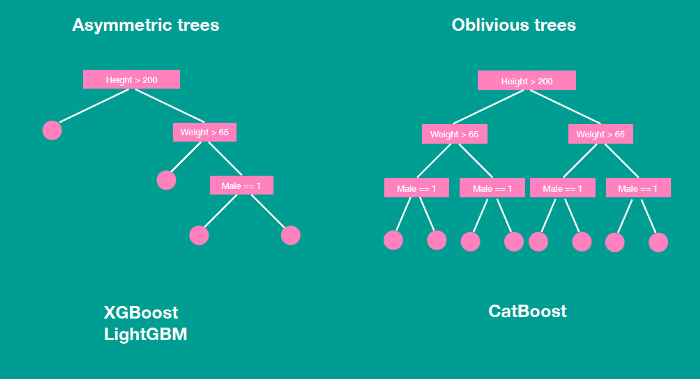
(참고 : https://youtu.be/2Yi_Jse_7JQ)
'Python > ML' 카테고리의 다른 글
| [RS] 컨텐트 기반 필터링 (Content-based Filtering) (0) | 2023.03.02 |
|---|---|
| [ML] Boosting - CatBoost 실습 (2) | 2022.09.11 |
| [ML] 모델에 대한 설명 - Shapley Additive Explanations(SHAP) (0) | 2022.09.06 |
| [ML] 모델에 대한 설명 - Partial Dependence Plots (0) | 2022.09.05 |
| [ML] 모델에 대한 설명 - Permutation Feature Importance (0) | 2022.09.05 |


