
오답노트
[NLP] Transformer 본문
http://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Japanese, Korean, Russian, Spanish, Vietnamese Watch: MIT’s Deep
jalammar.github.io
Transformer
Transformer는 RNN의 단점을 개선한 모델이다.
- Long-term dependency 문제 → Attention으로 해결
- t번째 hidden state를 얻기위해 t-1번째 연산이 필요하므로 병렬처리가 안되고, 계산 속도가 느림 → Parallelization
Architecture

Encoder
Multi-Head Self-Attention 와 Feed Forward Neural Network로 sub layer 로 구성되어 있다.
input이 Multi-Head Self-Attention를 거쳐서 Feed Forward Neural Network로 입력되는 구조로
이러한 Encoder가 N개의 layer로 구성되어 있다.
Encoder로 입력되는 input은 단어의 위치 정보를 인코딩하는 Positional Encoding 후 입력된다.
Decoder
(Masked) Multi-Head Self-Attention, Feed Forward Network 그리고 Encoder-Decoder Attention로 구성되어 있다.
Masked Multi-Head Self-Attention는 Masking을 통해 현재 단어보다 미래 단어에 대해 Attention을 주지 못하게 한다.
Encoder-Decoder Attention은 seq2seq와 비슷한 원리로 동작한다.
Encoder와 마찬가지로 Decoder로 입력되는 input은 단어의 위치 정보를 인코딩하는 Positional Encoding 후 입력된다.
Encoder와 마찬가지로 입력되는 input은 단어의 위치 정보를 인코딩하는 Positional Encoding 후 입력된다.
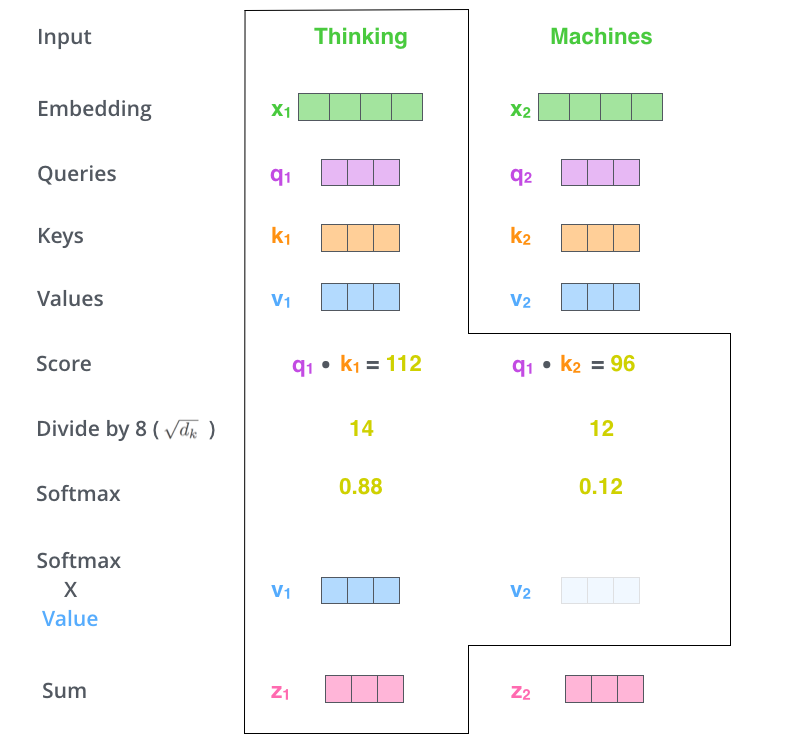
Self-Attention
Self-Attention로 입력된 벡터는 Query, Key, Value 가중치 행렬과 연산하여 각각의 Query, Key, Value 벡터를 만든다.

위 공식에서
Q 는 Query 벡터
K 는 Key 벡터
V 는 Value 벡터를 의미하고
d 는 차원을 의미한다.
d 는 차원이 커지면 분자의 곱이 계속 커지는 것을 방지해준다.
위 공식에서 softmax를 통해 다른 단어들과 비교하여 확률이 가장 높은 값을 Attention 벡터로 만든다.
Multi-Head Attention
설정한 병렬 연산되는 Attention개수 만큼 Attention 벡터를 만들어는데 이것을 Mult-Head Attention이라고 한다.
이렇게 만들어진 Mult-Head Attention를 concatenate하여 한 개의 Attention 벡터로 만든다.
이 Attention 벡터와 Output 가중치 벡터와 연산하여 만들어진 Attention 벡터를 최종적으로 출력한다.
Residual Connection (Add&Norm)
Residual Connection 은 기존 입력값에 서브레이어의 결과값을 더해줘(Add) 레이어를 거칠수록 gradient가 소멸되는 vanishing gradient 문제를 완화하여 심층 신경망 학습에 도움을 주고 이어서 Layer Normalization(Norm)을 통해서 gradient가 exploding하거나 vanishing하는 문제를 완화하고 안정적인 값을 가지게 되어 더 빨리 학습할 수 있게 된다.
FFNN (Feed Forward Neural Network)
FFNN 에 입력된 값은 우선 Linear 함수를 거치고 ReLu 함수를 거쳐 마지막으로 다시 한번 Linear함수를 거쳐 Encoder의 출력이 된다.
Linear & Softmax
Encoder 와 Decoder를 거쳐서 나온 벡터는 Linear layer를 거치면 단어 사전 크기의 벡터로 변환되서 출력된다.
이를 logits이라고 하고 이 logits은 softmax함수를 통해 단어를 예측하게 된다.
'Python > DL' 카테고리의 다른 글
| [NLP] N-gram (0) | 2022.10.14 |
|---|---|
| [NLP] BERT (0) | 2022.10.07 |
| [NLP] Sequence-to-Sequence (seq2seq) (1) | 2022.10.06 |
| [NLP] Long Short-Term Memory (LSTM) (1) | 2022.10.06 |
| [NLP] RNN (Recurrent Neural Network) (0) | 2022.10.06 |


