
오답노트
[YOLO] YOLO(You Only Look Once) - Object Detection 본문
Object Detection
ANN 또는 DNN으로 이미지를 예측하는 것은 기존의 자료구조를 파괴하여 예측했었다. 그래서 성능이 썩 좋지 않았다.
CNN은 이미지의 자료구조를 최대한 살려서 예측했고, 성능도 괜찮았다.
하지만 CNN은 객체만 존재하는 iconic-image에서만 강점을 보이고 non-iconic-image에는 다소 실망스러운 모습을 보인다.

non-iconic-image에는 사물이 한개가 아니라 여러 개가 포함되어 있다. 그렇기 때문에 CNN은 이를 제대로 예측할 수 없는 것이다. 그렇다면 사물이 여러 개 일 때는 어떻게 해야할까?
간단하다. 사물의 위치를 찾아내서 분류해내면 된다. 이것을 Object Detection이라고 한다.
Object Detection은 Localization과 Classification으로 이루어져 있는데, 각각 위치와 분류를 수행하는 것이다.
이 Object Detection은 One-Stage Object Detection 과 Two-Stage Object Detection으로 나뉘는데,
One-Stage Object Detection은 입력된 정보로부터 객체의 위치와 분류를 동시에 수행하고
Two-Stage Object Detection은 입력된 정보로부터 객체의 위치와 분류를 각각 수행한다.
즉 속도에서 One-Stage Object Detection가 더 빠른 것이다.
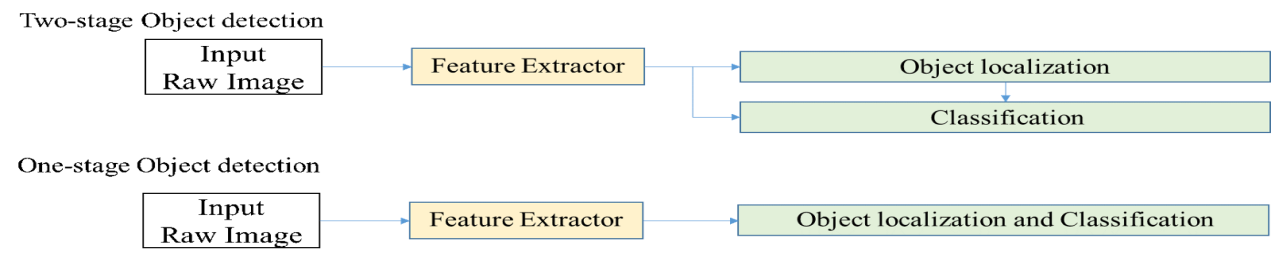
One-Stage Object Detection을 사용하여 빠르게 Object Detection 이 바로 YOLO이다.
YOLO (You Only Look Once)
YOLO는 One-Stage Object Detection을 통해 빠르게 객체를 검출해낸다.
YOLO의 객체 검출 프로세스를 살펴 보자.
YOLO는 이미 지도학습된 모델을 통해 다음과 같은 과정을 거친다.

- 입력된 이미지를 S x S Grid로 분할한다.
- 각 Grid cell에 B개의 Box를 그린다. 이 Box를 Bounding Box라고 한다.
- Bounding Box에 대한 Confidence Score(객체의 유무에 대한 확률)를 예측한다.
- 각 Grid cell은 C개의 조건부 클래스 확률을 갖는다.
- Bounding Box의 Confidence Score와 C개의 조건부 클래스 확률을 토대로 해당 Grid cell을 분류한다.
- Grid cell들을 통해 위치와 분류를 모두 수행한다.
Bounding Box
Grid cell에서 Bounding Box를 통해 Localization(객체의 위치)을 찾아낸다. 이때 Bounding Box는 5개의 값을 가지게 된다.
- x 예측값 : Grid cell 에서의 x 좌표
- y 예측값 : Grid cell 에서의 y 좌표
- width 예측값 : 전체 이미지에서의 너비
- height 예측값 : 전체 이미지에서의 높이
- Confidence score : Bounding Box내에 객체의 유무에 대한 확률
Bounding Box는 수치(Localization)를 예측하는 것이므로 회귀(Regression)이라고 볼수있다.
그래서 Localization을 Bounding Box Regression이라고 부른다.
Confidence Score
Confidence score는 Bounding Box내에 객체의 유무에 대한 확률이다.
예측하기 위한 Bounding Box에 대한 기준이 있어야 하는데 이를 ground-Truth Bounding box라고 한다.
ground-Truth Bounding box는 실제로 객체가 있는 Bounding box이고 ground-Truth Bounding box에 대한 Confidence score는 언제나 1의 확률을 갖는다.
그리고 우리가 객체가 있다고 예측하려는 Bounding Box의 Confidence score는 0~1 의 확률을 갖는다.
Backbone
CNN이 Object Detection에서 하는 역할이다. CNN은 위치 정보를 보존하여 Feature Representation하는 특징이 있다.
이 위치 정보는 Bounding Box Regression과 일맥상통한다.
Classification
객체의 위치에서 객체를 분류한다. CNN에서 하던 그것과 유사하다.
Head
Head는 Backbone 과정을 거쳐서 도출된 x(예측값), y(예측값), width(예측값), hight(예측값), Confidence score, Class 정보를 토대로 Fully Connection 를 통해 최종적으로 Object Detection의 결과를 도출한다.
'Python > DL' 카테고리의 다른 글
| [keras] ImageDataGenerator (0) | 2022.09.29 |
|---|---|
| [YOLO] Object Detection From Pretrained Model (0) | 2022.09.22 |
| [Keras] CNN 관련 레이어 - Conv2D, MaxPool2D (2) | 2022.09.21 |
| [DL] CNN (Convolutional Neural Network) (0) | 2022.09.19 |
| [Keras] 모델 성능에 유용한 Layer (0) | 2022.09.19 |

