
오답노트
[ML] 모델에 대한 설명 - Permutation Feature Importance 본문
Permutation Feature Importance
SVM 과 KNN 같은 알고리즘은 Feature Importance를 알 방법이 없다.
하지만 Permutation Feature Importance를 활용하면 알고리즘의 상관없이 변수 중요도를 파악할 수 있다.
Feature 하나의 데이터를 무작위로 섞고 예측했을 때, model의 Score가 섞기 전과 섞은 후 얼마나 감소되는지 계산하는 방식이다. 특정 Feature에 대해서, 여러 번 시도해서 나온 Score의 평균 계산하여 그것을 원래 model 의 Score와 빼 변수 중요도를 판별하는 방법이다.
하지만 다중 공성성이 있는 변수가 존재할 때, 관련된 변수는 그대로 존재하므로 Score가 줄어들지 않을 수 있다.
from sklearn.inspection import permutation_importance
pfi_knn = permutation_importance(m_knn_g.best_estimator_, x_val_s, y_val, n_repeats=10, scoring = 'r2', random_state=2022)
# 1 : feature별 Score 분포 kde
plt.figure(figsize = (12,8))
for i,vars in enumerate(list(x)) :
sns.kdeplot(pfi_knn.importances[i], label = vars)
plt.legend()
plt.show()
# 2 : feature별 Score 분포 box
sorted_idx = pfi_knn.importances_mean.argsort()
plt.figure(figsize = (12,8))
plt.boxplot(pfi_knn.importances[sorted_idx].T, vert=False, labels=x.columns[sorted_idx])
plt.axvline(0, color = 'r')
plt.grid()
plt.show()
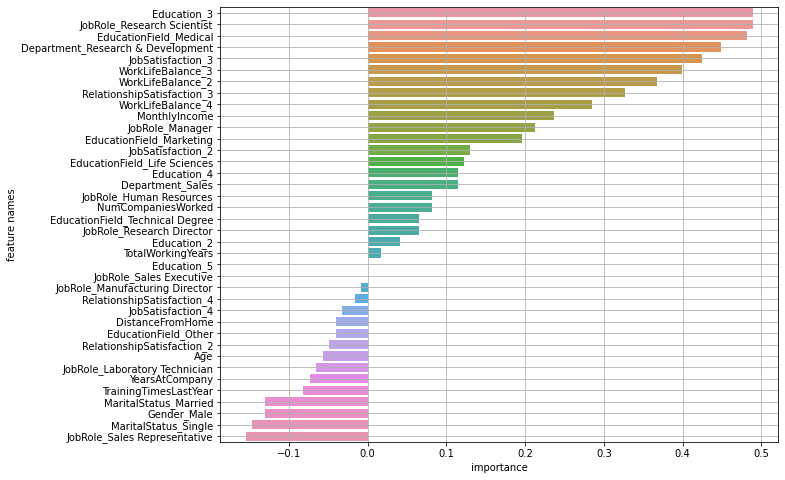
# 3 : 평균값으로 변수중요도 그래프 그리기
result = plot_feature_importance(pfi_knn.importances_mean, list(x_train))permutation_importance 옵션중 scoring은 예측의 종류에 따라 달라진다.
꼭 신경써서 사용하도록 하자

'Python > ML' 카테고리의 다른 글
| [ML] 모델에 대한 설명 - Shapley Additive Explanations(SHAP) (0) | 2022.09.06 |
|---|---|
| [ML] 모델에 대한 설명 - Partial Dependence Plots (0) | 2022.09.05 |
| [ML] 모델에 대한 설명 (0) | 2022.09.05 |
| [ML] 전통적 시계열 모델링 - ARIMA (0) | 2022.08.29 |
| [ML] 시계열 데이터 - 전통적 시계열 모델링 (0) | 2022.08.29 |
'Python/ML' Related Articles
more


