
오답노트
[ML] 비지도 학습 - k-means 본문
k-means

(출처 : https://stanford.edu/~cpiech/cs221/handouts/kmeans.html )
k-means는 데이터를 좌표평면에 위치시킨 후 임의의 위치에 k개 점을 찍는다. 그리고 각 데이터들은 k개의 점들중에 가장 가까운 점에게 군집된다.
그 후 k 개의 점은 군집된 데이터들의 중심 위치로 재위치 시킨다. 그리고 다시 데이터들이 k개의 점들중 가장 가까운 점에게 군집되는 과정을 중심 위치의 변화가 거의 없을 때까지 반복한다.
위 과정이 걸리는 시간은 매우 빠르지만 k는 모델링을 할 때 우리가 정해줘야한다. (비지도인데 지도를 해야한다니..)
k 값 선정 방법
Inertia value를 통해서 k 값을 유추해 볼수있다.
Inertia value는 군집화가 된 후, 각 중심정에서 군집의 데이터간 거리를 합산한 값이다.
이는 군집의 응집도를 나타내는데, 값이 작을 수록 응집도가 높게 군집화가 잘 되었다고 할 수 있다.
즉, k에 따른 Inertia value의 변화량을 봤을 때 그래프가 급격하게 변하는 곳 주변에서 적절한 k 값을 유추할 수 있다.
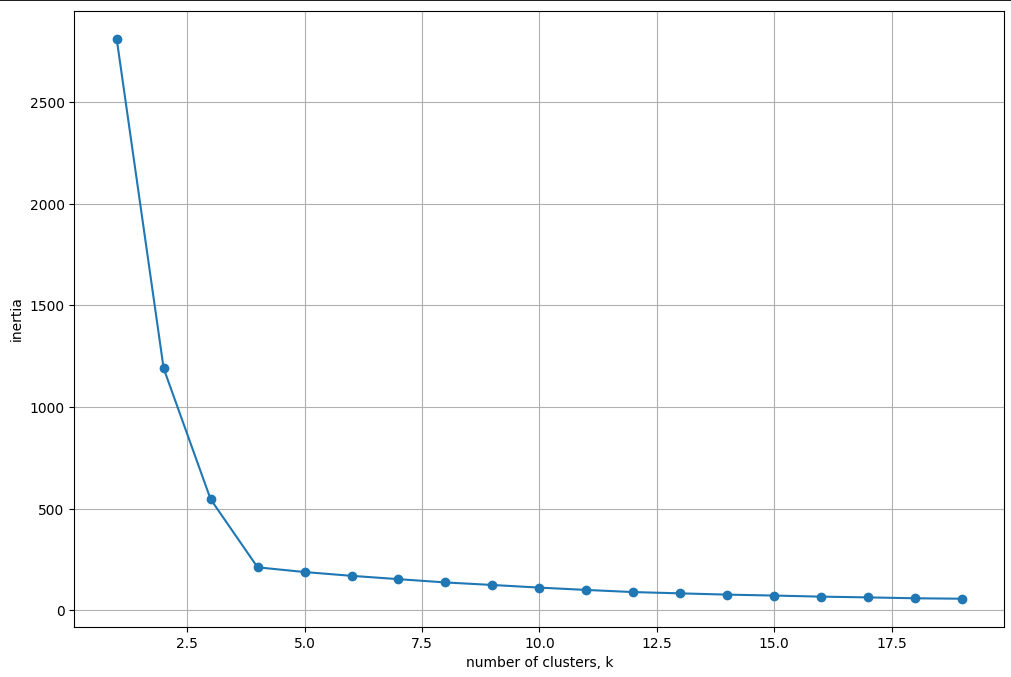
위 그래프는 k에 따른 Inertia value의 변화량 그래프이다. k가 작아질 수록 0에 수렴하고 있다. 군집화는 잘 되었지만 과적합 상태이다. 위 그래프에서는 2.5 이상 5미만의 값에서 k를 유추하는 것이 좋아보인다.
'Python > ML' 카테고리의 다른 글
| [ML] 시계열 데이터 (0) | 2022.08.29 |
|---|---|
| [ML] 비지도 학습 - DBSCAN (0) | 2022.08.29 |
| [ML] Boosting - Gradient Boost (0) | 2022.08.26 |
| [ML] 앙상블 - Boosting (0) | 2022.08.26 |
| [ML] Bagging - Random Forest (0) | 2022.08.25 |
'Python/ML' Related Articles
more

